功能说明
本功能通过根据一些泛目录网站的网址特点,制定出符合网址规律的URL规则。软件可以模拟出大量的此规则的泛目录网址,访问这些网址,从而分析网址的Title等数据,从而达到采集整站关键词的功能。特别说明:考虑到有些网站会针对性的做防采集措施,导致本功能不是所有泛目录网站的关键词都可以保证提取到。
功能主界面
采集设置
- 提取方式
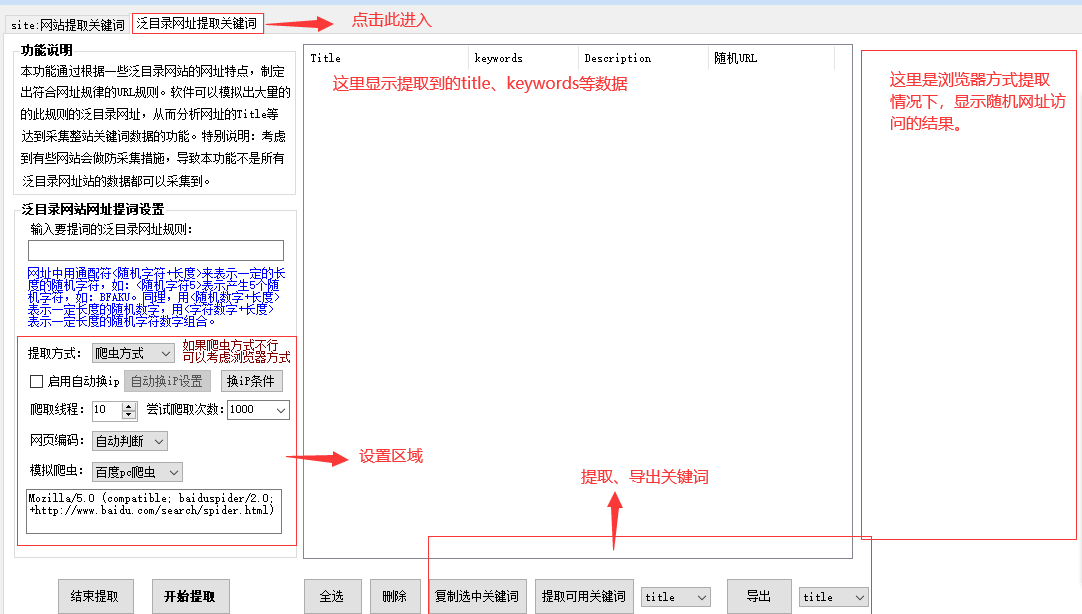
工具提供“爬虫方式”和“浏览器方式”两种提取方式。“爬虫方式”就是工具模拟各种搜索引擎爬虫(可自己选择或设置)访问根据规则产生的随机页面获取数据。“浏览器方式”是指工具内置浏览器,直接访问根据规则产生的随机页面获取数据。“爬虫方式”访问效率高,可多线程运行,但是各网站目前都有针对性的防抓取就是针对“爬虫模式”,因此此模式下,采集的成功率不是很高,相反,“浏览器模式”无法多线程只能挨个随机页面分析提取关键词,但是这个模式相对成功率较高一些。 -
尝试爬取次数:
本功能根据规则不断产生的随机网页,访问这些网页获取关键词,尝试爬取次数就是根据规则产生的随机网页的次数,理论上每随机爬取一个网页就可以提取到一个关键词。 - 网页编码
网页编码一般分为“gb2312”和“utf-8“两种,也可以选择软件自动判断,如果编码没选好,可能导致获取的数据是乱码。 - 模拟爬虫
这里的爬虫就是为”爬虫方式“提取关键词时候调用,可以选择具体的搜索引擎爬虫,也可以输入自定义爬虫。 - 启用自动换IP
 当频繁访问某个泛目录网站的随机网页时候,可能会触发网站的防屏蔽措施导致获取不到网页数据。有些网站是针对访问IP限制,这时候可以通过换IP的方式来解除限制。点击”换ip条件“可以设置当访问的网页数据满足一定条件时(被封)启用自动换IP,如下图:
当频繁访问某个泛目录网站的随机网页时候,可能会触发网站的防屏蔽措施导致获取不到网页数据。有些网站是针对访问IP限制,这时候可以通过换IP的方式来解除限制。点击”换ip条件“可以设置当访问的网页数据满足一定条件时(被封)启用自动换IP,如下图:
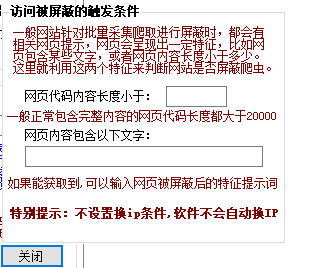
一般被封后,获取的网页数据会不正常,展示一定的提示语句如”你的访问太过于频繁“等,或者网页内容特别短,正常网页有几万字节,屏蔽后提示内容的网页一般只有一万不到的字节。工具提供判断网页的内容长度,和判断网页包含内容两种方式来判断是否屏蔽。当满足设置的屏蔽条件,将触发换IP,根据你设置的换IP方式工具会启用换IP。一般情况下建议”爬虫方式“提取,用代理IP方式换IP,”浏览器方式“提取,用拨号adsl服务器方式换IP。
数据导出

正常情况下本功能提取完毕后,数据列表中显示的是默认获取的原始的网页的titile、keywords、description三种数据,这些数据里包含关键词信息和网站信息,一般形式是关键词+分隔符+网站名称,点击"提取可用关键词",可将数据列表中的原始数据提取到只剩下关键词数据。然后点击”导出“选择要导出的具体titile、keywords、description里的关键词数据。